Knative v0.3 Autoscaling — A Love Story ¶
Published on: 2021-10-06 , Revised on: 2024-01-09
Knative v0.3 Autoscaling — A Love Story¶
Author: Joseph Burnett, Software Engineer @ Google
Knative v0.3 Autoscaling — A Love Story
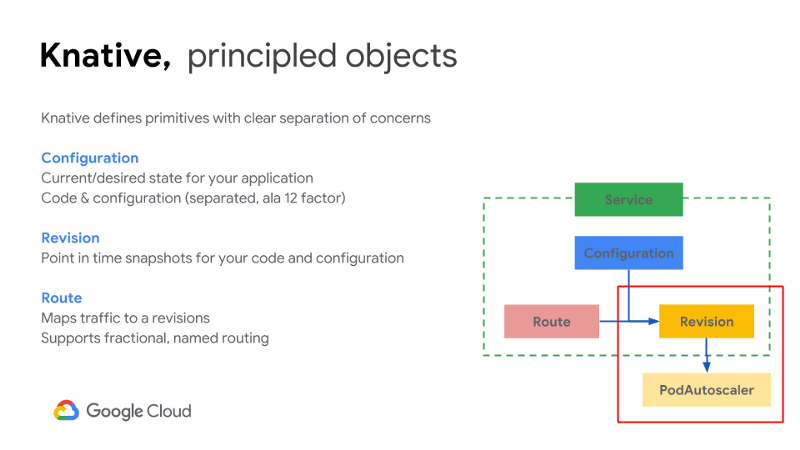
Scaling in the Knative v0.3 release includes new options for customizing the autoscaling subsystem. From a batteries-included, scale-to-zero default, to an ability to replace the autoscaling system entirely, and everything in between. PodAutoscaler, the new custom resource in Knative, provides an extension and control point with which to configure your application.
To illustrate these options, let’s walk through the evolution of a Web application from inception to complex autoscaling. We promise, “Knative Autoscaling will grow old with you.”
I just wanna keep it simple
One morning, you sit bolt upright in bed struck by the realization that what people really want… is love. You write a quick Web application to apply a heart-shaped watermark to any given image in just the right place. Since you’re a savvy, modern application developer, you drop it in a container and spin it up on a Knative Service on GKE with `gcloud run deploy — image gcr.io/joe-does-knative/love`.
This is what your Knative Service looks like:

You show it to your BFF and they post it on Hacker News. Voila, you’re on the front page of the hacker’s Internet! HN tries to give you the hug-of-death, but your application and cluster scales up to handle 1000 op/s of traffic seamlessly. After a while, the excitement dies down and your service is getting 1 or 2 requests per hour. Luckily, Knative scales to zero Pods when not in use, so you don’t spend money running an idle process. And you never changed anything after the initial deployment! That was simple.

Please don’t go away
Several weeks later, lightning strikes again and you realize… “I could make money doing this”. Clearly people enjoyed the heart-shaped watermarks. Maybe you could let people use your service to watermark images on their entire website! Adding a quick in-memory cache in front of your Ruby script (yeah, it’s Ruby) you redeploy and then start advertising your product as a general image-processing service. Things are going well, but you quickly realize that your traffic is unpredictable — it bursts a lot. And when the service scales to 0 Pods and later the traffic resumes, you spend the first few minutes building up the cache again, which makes request latency a little too high. So you decide to add an annotation to your Knative Service’s Revision template to maintain at least 2 Pods at all times.
This is what your Knative Service looks like now:

Things aren’t scaling to zero. But that’s fine because you’re making a little money from the venture.
Things are heating up
Woah! Traffic is starting to ramp up. You’re averaging about 500 op/s and running between 10 and 50 Pods depending on the time of day. You’ve noticed that this job is mostly CPU-bound and you’re not utilizing all your resources as efficiently as you could. So you make some adjustments to the default autoscaling target:

But eventually you conclude that you just need to scale on CPU to keep your machines hot. So you choose a different Knative autoscaling class entirely. The class annotation will tell Knative to use a different PodAutoscaler controller implementation, kinda like Kubernetes Ingress.
Here is your Knative Service now:

Running at 60% CPU consistently you’re actually starting to make more money than you’re spending! So you quit your day job to pursue heart-shaped watermarking full time.
Let’s get serious
Things are getting complicated. Seeking professional help, you hire Dr. Mark to help you run your service operations. One of the first things he implements is rollout mode for your service. No more leaping before you look!
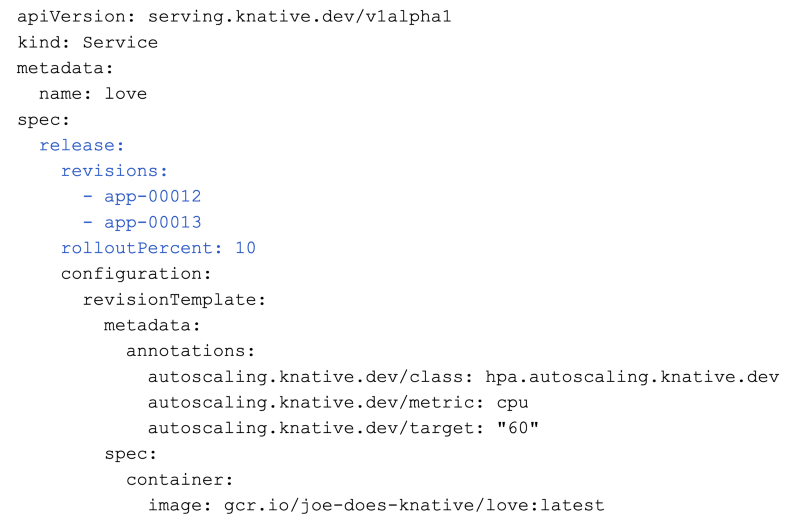
Things are smooth sailing with Dr. Mark at the helm! As the weeks roll on, New Year’s Eve approaches and you start seeing non-linear growth in your metrics. A quick consultation with Dr. Mark confirms your worst fears. People go crazy sending each other pictures with hearts on New Year’s Eve. And they do it all at the same time like they are coordinating a DDOS attack of love. You’re going to need a plan.
Luckily, Dr. Mark has been doing his reading in the Knative Serving release notes and begins experimenting with editing the PodAutoscaler on pre-existing Knative Revisions. The PodAutoscaler is where Knative keeps its autoscaling state and configuration for a Knative Revision. And unlike the Knative Revision, it’s mutable (on purpose). You make a plan to ramp up capacity slightly ahead of traffic as it builds to each NYE event across the globe (yeah, it happens 24 times!)

Over the course of the evening, New Year’s marches from timezone to timezone. You see a few minutes of errors on the first NYE event because the CPU target of 60% is too high. But after you adjust it down to 40% for the next event, it’s smooth sailing for the rest of the evening. Hooray! 🎉
You’re so special
It’s been a full year and things have been crazy! You’ve done some deep integrations with several major image hosting websites and they are driving like 80% of your traffic and revenue now. With a little time on your hands, you start analyzing your autoscaling statistics. You realize that traffic observed by your upstream referrers almost perfectly predicts your traffic patterns. And they can give you those metrics through your API integration!
But you have implemented your CI/CD pipeline to work with Knative. And all your operational experience is in running Knative workloads. It would be a shame to throw all that out just to implement your own autoscaling algorithm. But then you remember something Dr. Mark said way back when he started looking in to Knative v0.3. With the PodAutoscaler custom resource, you can implement your own reconciler and autoscaling system without changing anything else about the Knative Serving system. Well, there you go!
A quick copy of a Kubernetes sample-controller and you’ve implemented a reconciler that operates on your own class of Knative PodAutoscaler. It queries upstream metrics to scale predictively.
This is what you have to change in your Knative Service to wire it up:
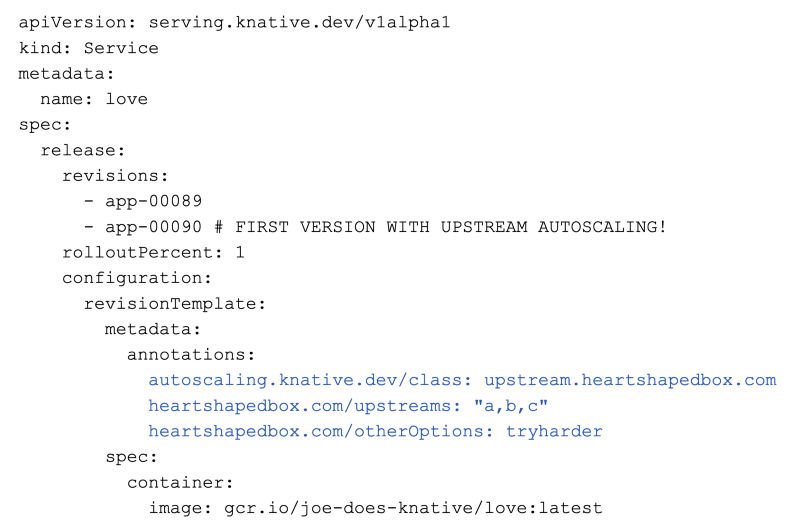
Wow. Controllers and autoscalers are hard to write. But it’s a core problem for your business and you’ve got it up and running. And you didn’t have to touch all the other stuff that wasn’t related to this particular autoscaling problem. As you think on how Knative has grown with your business over the last couple years, you just gotta say “I got options, but Knative … you’re the top one!”
What happened?
To learn more about how the PodAutoscaler works and the options that Knative autoscaling has, please watch the Kubecon talk Knative: Scaling From 0 to Infinity and checkout the code on Github. Or play around with the Knative Serving autoscaling sample.
This is where the PodAutoscaler sits in relation to the other Knative entities: